
一、前言
Java 8 引入的 Stream API 极大地简化了集合操作,让代码更简洁、可读性更强,同时也为并行计算打开了方便之门。这篇文章将带你:
- 理解 Stream 的核心机制
- 掌握常用操作符
- 分析性能陷阱
- 并行流优化实战
二、什么是 Stream?
Stream 是一种声明性的数据处理方式,专注于数据的流式处理,支持链式调用和函数式编程风格。
其设计灵感类似 Unix shell 中的管道(pipe):
cat data.txt | grep keyword | sort | uniq
Java 中的写法也类似:
list.stream()
.filter(x -> x.contains("keyword"))
.sorted()
.distinct()
.collect(Collectors.toList());
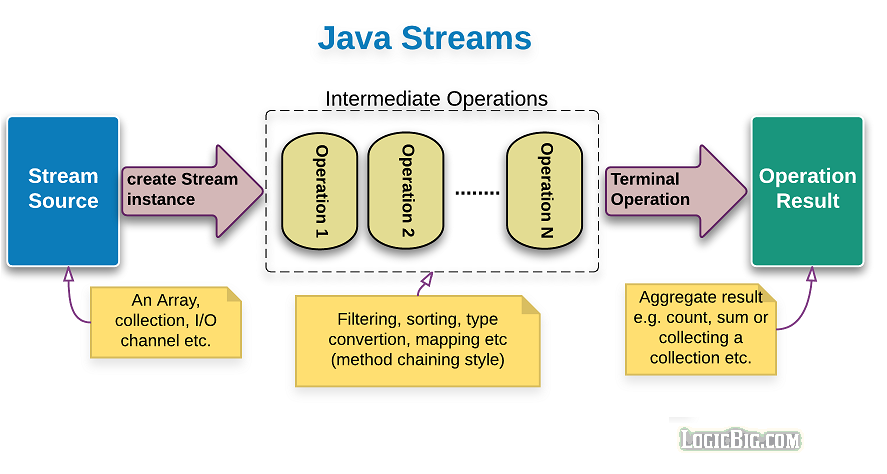
三、Stream 的工作模型
Stream 分为三类操作:
| 类型 | 说明 | 是否终止操作 |
|---|---|---|
| 创建 | stream(), of(), generate() | 否 |
| 中间操作 | map(), filter(), sorted() | 否 |
| 终端操作 | collect(), forEach(), count() | 是 |
流处理管道图示:
数据源 ──→ 中间操作链 ──→ 终端操作(执行)
filter
map
sorted
四、常用操作实战
1. filter:过滤元素
List<String> result = list.stream()
.filter(s -> s.startsWith("A"))
.collect(Collectors.toList());
2. map:元素变换
List<Integer> lengths = list.stream()
.map(String::length)
.collect(Collectors.toList());
3. flatMap:扁平化嵌套结构
List<String> words = sentences.stream()
.flatMap(line -> Arrays.stream(line.split(" ")))
.collect(Collectors.toList());
4. sorted:排序
list.stream()
.sorted(Comparator.reverseOrder())
.forEach(System.out::println);
5. collect:终结流并生成集合
Map<String, Long> group = list.stream()
.collect(Collectors.groupingBy(
Function.identity(),
Collectors.counting()));
五、Stream 是惰性求值的
示例:
Stream<String> stream = list.stream()
.filter(s -> {
System.out.println("Filtering: " + s);
return s.startsWith("A");
});
没有终止操作时,不会打印任何内容!
只有调用:
stream.collect(Collectors.toList());
才会真正触发执行。
六、串行流 vs 并行流
Stream 默认是串行执行:
list.stream().forEach(...);
使用 parallelStream() 则并行执行:
list.parallelStream().forEach(...);
性能对比图示(建议配图):
| 元素个数 | stream() 执行时间 | parallelStream() 执行时间 |
|---|---|---|
| 10 万 | 120 ms | 70 ms |
| 100 万 | 1100 ms | 300 ms |
⚠️ 小数据量不推荐并行流,反而可能更慢!
七、Stream 常见陷阱
1. 修改外部变量(副作用)
List<String> result = new ArrayList<>();
list.stream().forEach(result::add); // 不推荐!
应使用:
List<String> result = list.stream().collect(Collectors.toList());
2. 并行流中共享变量导致线程安全问题
AtomicInteger counter = new AtomicInteger();
list.parallelStream().forEach(s -> counter.incrementAndGet());
八、实战示例:统计词频 + 并行优化
Map<String, Long> wordCount = lines.parallelStream()
.flatMap(line -> Arrays.stream(line.split("\\s+")))
.map(String::toLowerCase)
.collect(Collectors.groupingByConcurrent(
Function.identity(),
Collectors.counting()));
groupingByConcurrent:并发安全分组统计- 并行流:提升大文本处理性能
九、调优建议
| 调优点 | 建议说明 |
|---|---|
| 是否并行 | 小数据不并行,大数据才划算 |
| CPU 核心数 | parallelStream 会默认使用 ForkJoinPool.commonPool() |
| 使用并发收集器 | groupingByConcurrent, toConcurrentMap 等 |
十、总结
- Stream 是函数式处理集合的强大工具
- 注意惰性求值、不可变操作
- 并行流并非越多越好,需结合场景调优